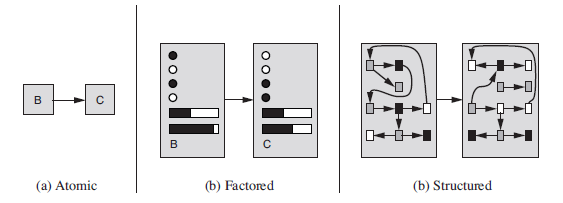
Figure 2.1
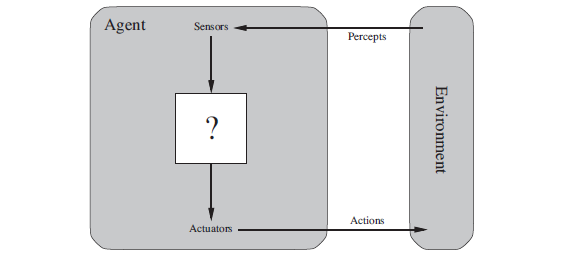
Figure 2.2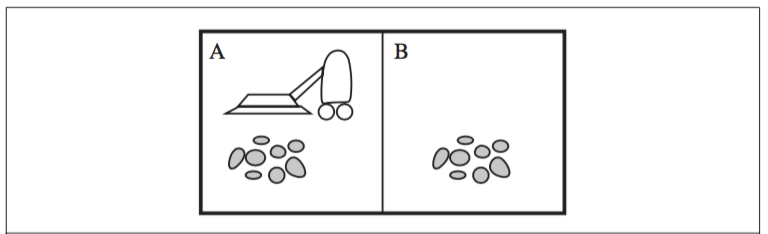
Figure 2.3
Figure 2.4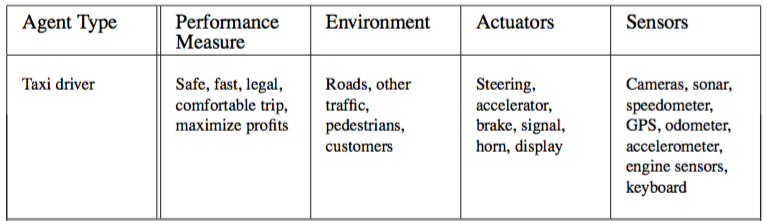
Figure 2.5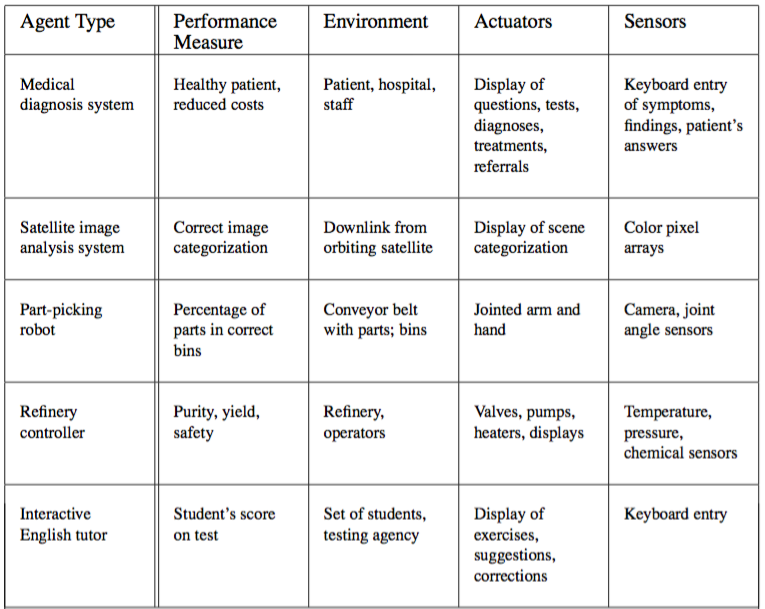
Figure 2.6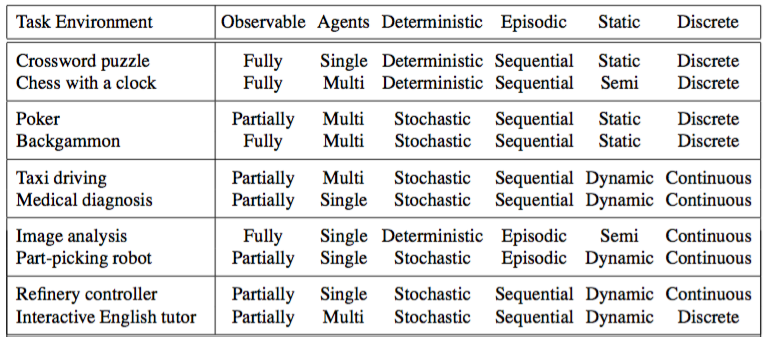
ちなみに、エージェント関数が受けとるのは知覚シーケンスなのに対して、エージェント・プログラムが受けとるのはその時点での知覚のみであることに注意。
過去の知覚も含めて判断したい場合は、エージェント・プログラムは必要に応じて内部で記憶しておくというわけ。
Figure 2.2
Figure 2.9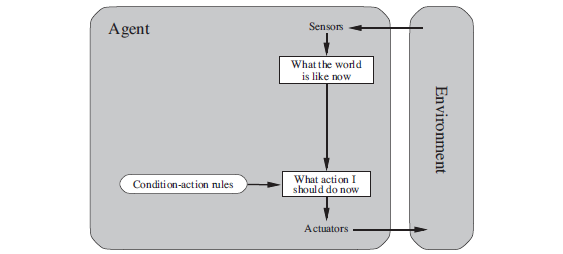
Figure 2.11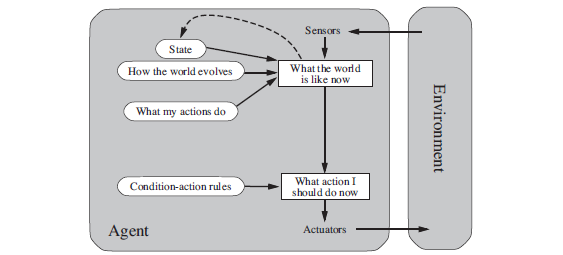
Figure 2.13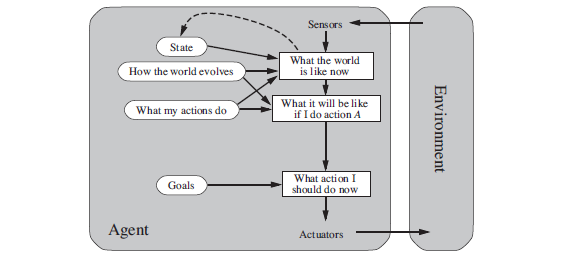
Figure 2.14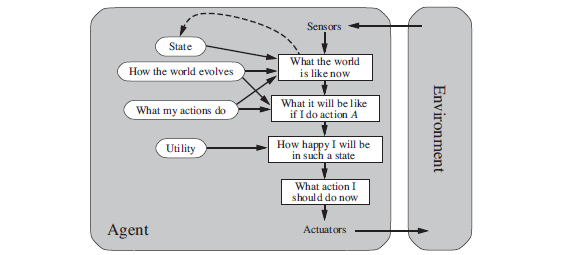
Figure 2.15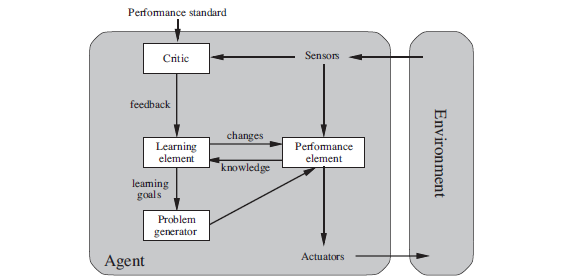
Figure 2.16